RAG agent
What is a RAG agent?
The RAG Agent is designed to answer user questions using knowledge extracted from unstructured documents (like manuals, reports, or résumés) you provide. It is AI-powered and designed to understand and answer questions based on the content of unstructured documents. You can ask questions across your uploaded documents, workspace files, or indexed knowledge sources. The agent reads, retrieves, and summarizes intelligently. It excels at document understanding and providing contextual answers by retrieving relevant information from a knowledge base of uploaded files.
The RAG agent enhances your ability to quickly extract information from documents with the following key capabilities:
-
Document understanding: It answers questions based only on the content of the indexed documents, ensuring responses are factual and grounded in your data.
-
Contextual retrieval: It retrieves and synthesizes relevant passages from the document set to formulate a precise answer.
-
Source citation: It provides clickable links next to the answer, showing the exact source document (or section) the information was pulled from.
-
Multi-format support: It supports various file types for ingestion, including PDFs, DOC files, CSVs, and XML files.
-
Image retrieval (advanced): It can retrieve and display relevant images, diagrams, or flowcharts from the source documents (especially PDFs) alongside the text response to fully illustrate the context.
Indexing duration for RAG agent is estimated rather than calculated precisely by a singular formula. The final time is dependent upon the processing load required for the document.
The estimation model accounts for the following key factors:
-
Document size: Larger file sizes inherently increase the time required for reading, transfer, and processing.
-
Resolution and complexity: Documents with higher resolution or intricate layouts (e.g., nested tables, multi-column formats) necessitate more intensive computational processing.
-
Page count: This is a direct linear factor; a greater number of pages correlates directly to more content requiring analysis and indexing.
-
Image/media count: Documents containing numerous images, graphs, or embedded media demand additional processing for image analysis, feature extraction, and Optical Character Recognition (OCR) on any text within those visual elements.
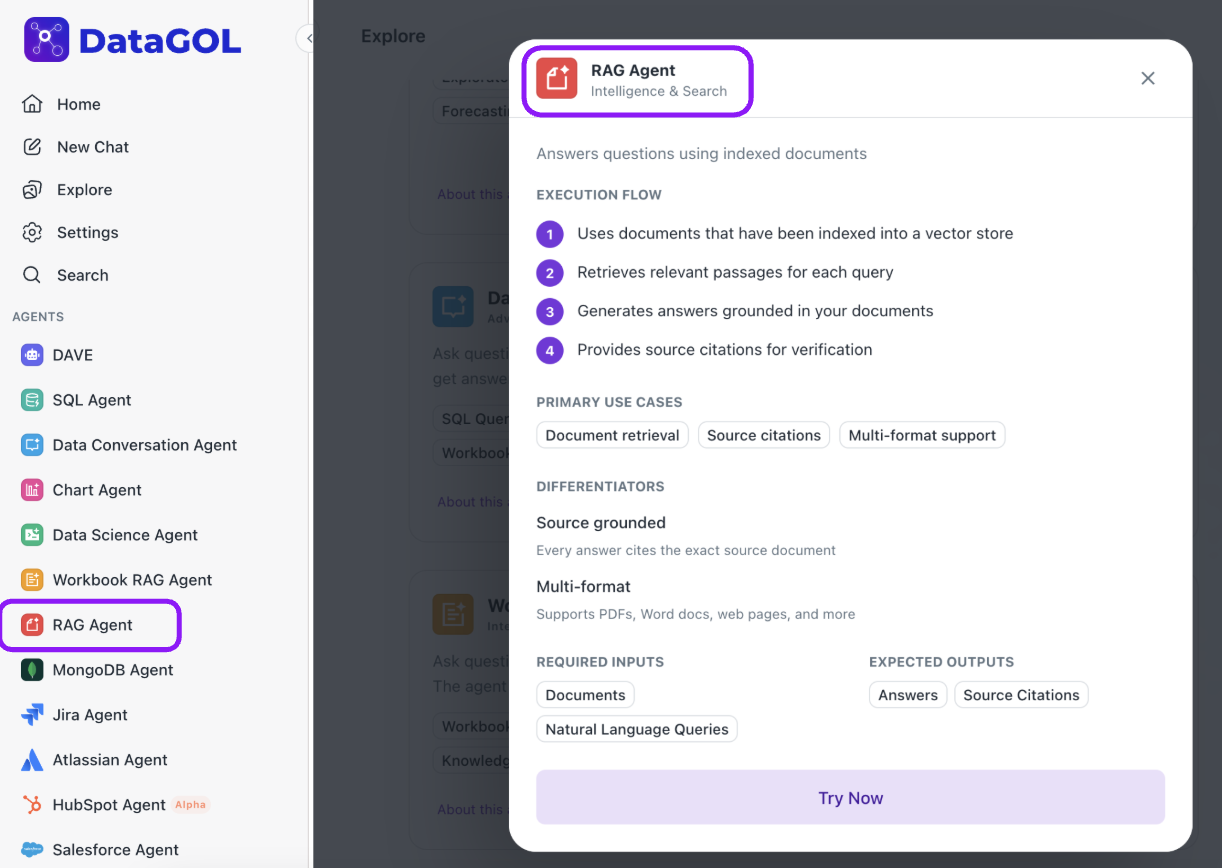
Configuring the RAG agent
The RAG agent configuration primarily involves uploading and indexing your documents within a workspace.
-
Select a workspace: Navigate to the Explore section and select the RAG agent. You will then choose an existing workspace where your documents are stored or create a new one.
-
Upload documents: Within your chosen workspace, go to the Documents section. You can upload various file types, such as PDFs, Word documents, CSVs, and XML files.
-
Monitor indexing status: After uploading, a status indicator (a green tick mark in the list view or a "completed" status) will show if the file has been successfully indexed. Indexing means the file's content has been processed and added to the RAG agent's knowledge base, making it searchable and available for answering questions.
Using the RAG agent
Once your documents are indexed, you can start asking questions to the RAG agent.
-
From the DataGOL Home page, navigate to the Agents section.
-
Click RAG agent.
-
On the RAG agent's chat page, ensure the correct workspace (the one containing your indexed documents) is selected. This is indicated by a green tag showing the workspace name.
-
Type your question into the chat interface. The agent will then retrieve information from the indexed documents within the selected workspace to provide an answer.
Examples of usage:
- "What is John Doe's educational background?" (If "John Doe's resume" is indexed)
- "Can you help me understand the Lakehouse module?" (If a product manual with a "Lakehouse module" section and relevant images is indexed)
From the generated responses, you can do the following:
-
Review source documents: If the answer is derived from a specific document, the agent will indicate which document. You can click on this reference to be taken directly to the source document for verification.

-
Visualize relevant images: If your query's answer references an image within the source PDF, the RAG agent will display that image alongside the textual response for better context.

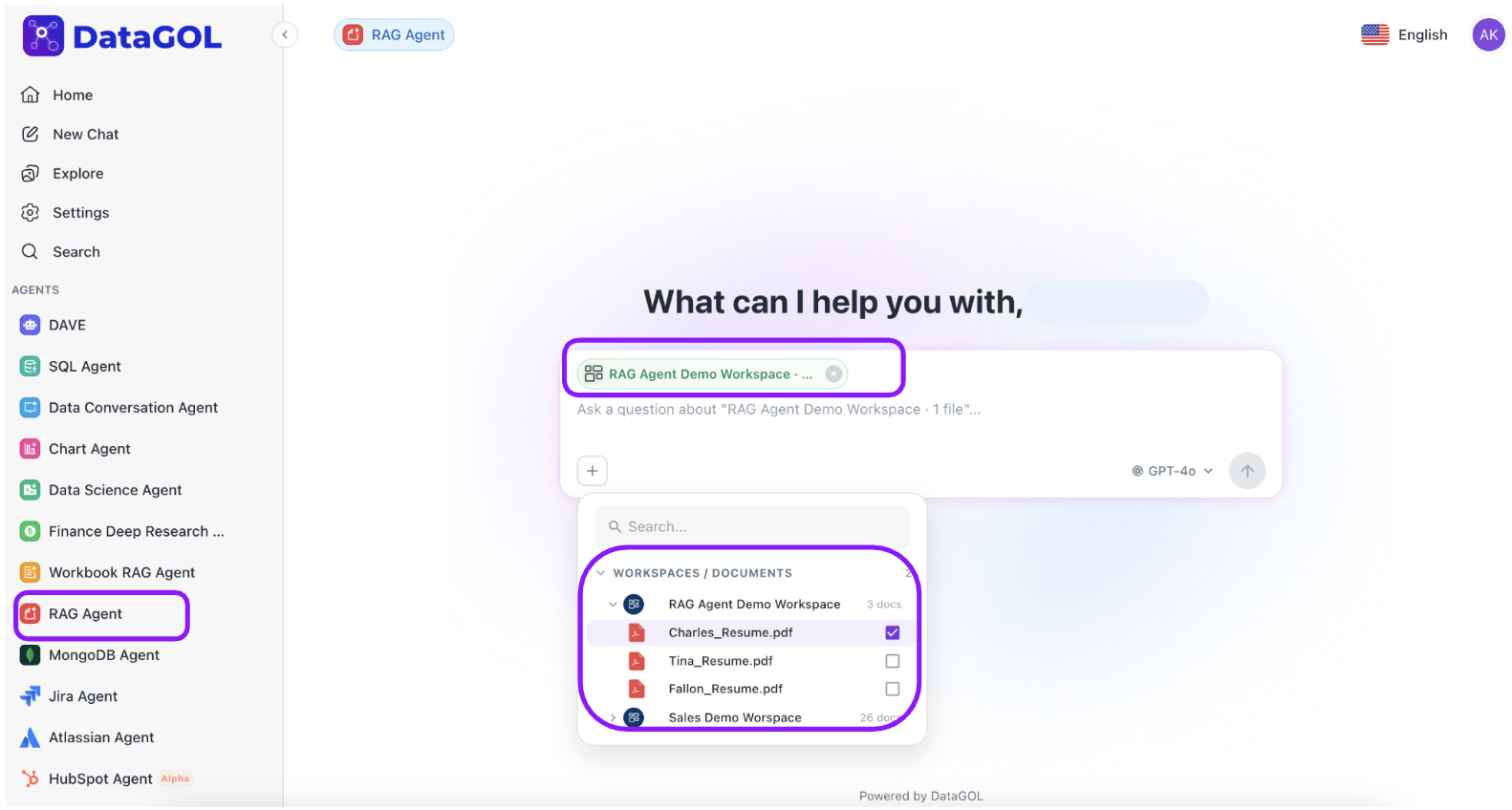
Adding specific context to your RAG agent queries
You can select specific documents and folders to guide the agent and narrow its focus, ensuring your results are based on the exact information you need.
-
Click "+ icon": In the RAG Agent UI, click the new + icon. This opens a selector showing all workspaces containing documents.
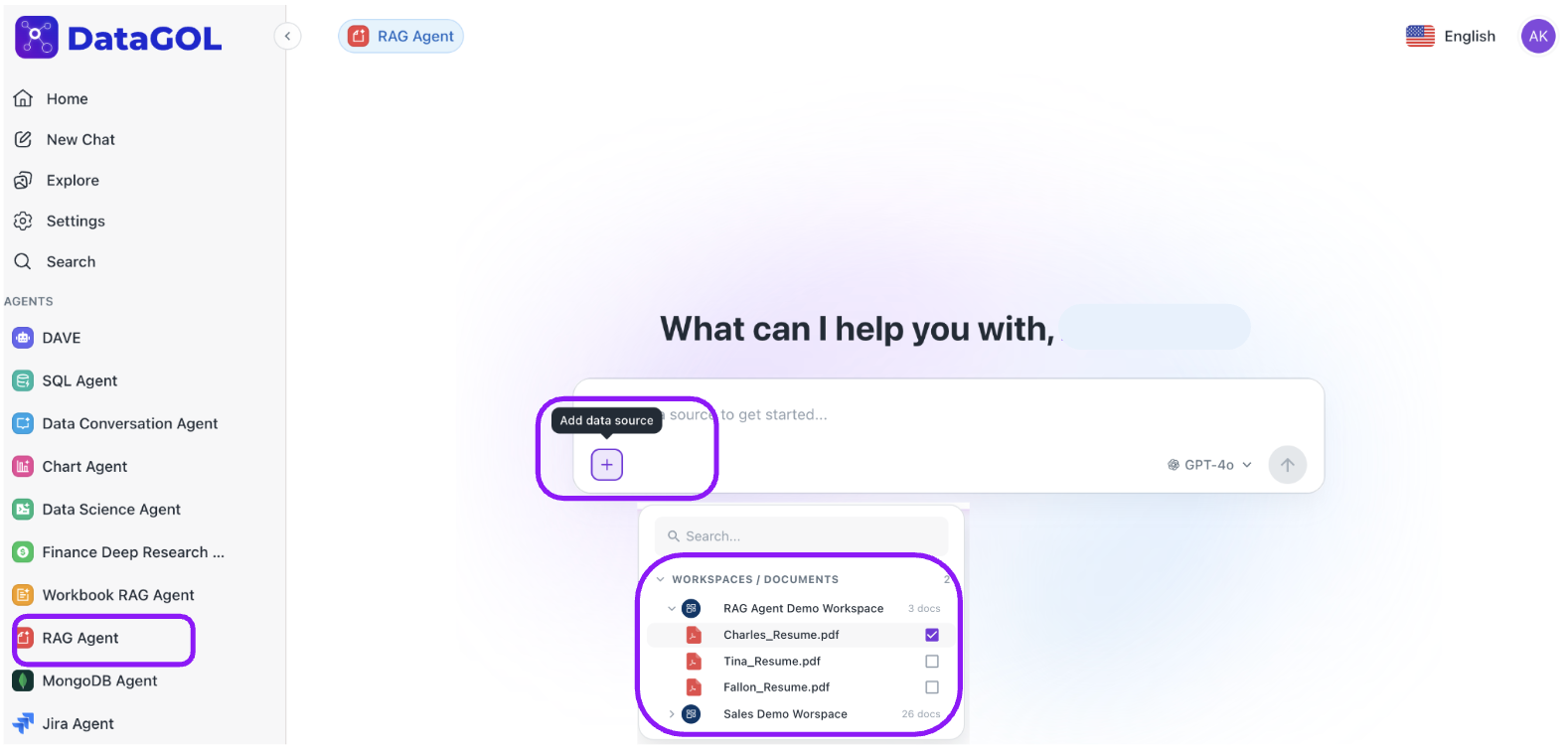
-
Select your sources:
- You can choose any AI-ready document.
Please ensure all documents are marked as AI Ready before selecting them in the datasource dropdown. Documents that are not yet indexed will not be available for selection and may affect your agent's ability to retrieve accurate responses. You can do this by checking the documents status from the Document Index Settings option mentioned below.
- Query the agent: When you submit your question, the RAG Agent will use the documents you selected as a primary source of information, leading to more focused and relevant answers.
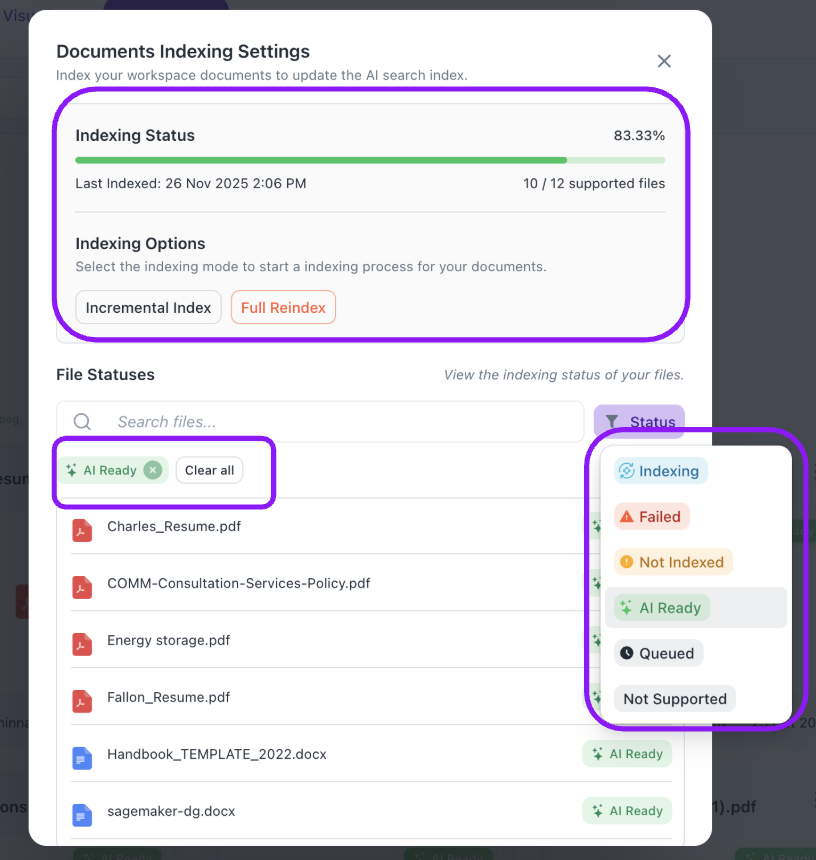
Document Indexing Settings – Workspace
Users can now manage and monitor the indexing status of all workspace documents directly from the Documents tab. The new Documents Indexing Settings panel gives full visibility into what's AI-ready and what still needs to be processed — so you always know exactly what your RAG agent can and cannot answer questions about.
What's New
- Indexing Status Overview – See the overall indexing progress at a glance, including the percentage of files indexed and the last indexed timestamp.
- Incremental Index – Process only newly added or updated documents, keeping your index current without a full reprocess.
- Full Reindex – Reprocess all documents in your workspace to ensure the AI search index is completely up to date.
- File-Level Status Visibility – Browse and search individual files to see whether each document is AI Ready or still pending — so you know exactly what your RAG agent can reference when answering questions.
Was this helpful?